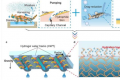
机器学习工具A-Plus为液体活检奠定了基础
希望之城和转化基因组学研究所(TGen)的研究人员开发并测试了一种机器学习方法,他们认为有一天可以仅使用少量抽血,对患者进行基于血液的早期癌症检测。该技术基于一种名为AluProfileLearningusingSequencing(A-PLUS)的算法,该团队在四组患者中开发、验证和测试了该算法,涵盖了来自乳腺癌、结肠和直肠、食道、肺部患者的数千个样本、肝癌、胰腺癌、卵巢癌或胃癌。

A-PLUS根据血浆细胞游离DNA中Alu元素的表现来区分患有癌症的个体与未患癌症的个体。新报告的研究结果发现,A-PLUS工具在11种研究的肿瘤类型中识别出一半的癌症。该测试也非常准确,假阳性率仅为百分之一。重要的是,测试的大多数癌症样本来自早期疾病患者,他们在诊断时很少或没有转移性病变。
“大量证据表明,晚期发现的癌症会致命,”希望之城癌症预防和早期检测中心主任、研究人员在《科学转化医学》杂志上的研究通讯作者CristianTomasetti博士说。“这项新技术让我们更接近这样一个世界:人们每年都会接受血液检查,以便在更容易治疗和可能治愈的时候更早地发现癌症。”研究人员的论文标题为“机器学习检测癌症正弦波”。他们在报告中得出结论:“因此,对Alu元素的评估可能有可能提高多种癌症早期检测方法的性能。”
Tomasetti解释说,99%被诊断患有1期乳腺癌的人五年后仍能存活;然而,如果在第4阶段发现,即疾病已扩散到其他器官时,五年生存率就会下降至31%。
作者解释说,Alu元件是约300个碱基对的短散布核元件(SINE),在整个人类基因组中分布有超过100万个拷贝。虽然这些元素是正在进行的研究的主题,但有些元素已被证明参与组织特异性基因的调节。科学家们写道:“在癌细胞中,它们可能通过同源重组参与结构变化,因为它们在整个基因组中广泛分布且序列高度相似……Alu序列元件在各种癌症中特别容易发生表观遗传变化,这是有很多先例的。”
研究人员没有通过从数十亿个字母中寻找一个错误排列的字母来分析特定的DNA突变,而是设计了一种新方法来检测癌症和正常游离DNA(cfDNA)重复区域中片段模式的差异。托马塞蒂说,这种片段组学方法所需的血液比全基因组测序所需的血液少约八倍。
当细胞死亡时,它会分解,细胞的一些DNA物质会渗入血液中。可以在该cfDNA中找到癌症信号。正常细胞的cfDNA在典型大小处分解,但癌症cfDNA片段在改变的位置分解。假设这种改变更多地存在于基因组的重复区域中。“Alu元素也反映了癌症患者cfDNA中发现的片段模式的改变,”科学家们继续说道。他们假设癌症患者血浆的无细胞DNA(cfDNA)中特定Alu元素的表现可能与正常对照的cfDNA不同。
由于基因组中有如此多的Alu元件,评估这一假设需要开发机器学习工具,该团队开发了A-PLUS,根据cfDNA中Alu元件的表示来区分患有癌症的个体和未患癌症的个体。
该机器学习平台在四个独立的患者队列中进行了训练和验证,总共有来自5178人的7615个样本,其中2073人患有实体癌症,其余的没有癌症。研究小组解释说:“癌症患者和对照患者的样本被预先指定为四个队列,用于模型训练、分析物整合以及阈值确定、验证和重现性。”
他们的结果表明,在验证队列中,仅A-PLUS对11种不同癌症类型的敏感性为40.5%,特异性为98.5%。将A-PLUS与非整倍体和八种常见蛋白质生物标志物相结合,以98.9%的特异性检测出51%的癌症。
该团队表示,A-PLUS的强大功能可归因于一个功能,“……实体癌患者循环DNA中AluS亚家族元素的整体减少。”他们进一步评论道:“......我们的研究表明,一般而言,Alu元素的表达,特别是AluS亚家族元素,在许多不同癌症类型患者的cfDNA中发生了改变......未来对其表达改变背后的机制的研究将有助于它们在基因组中的丰度以及相似的序列和结构。”
“我们的技术对于临床应用来说更实用,因为它需要从血液样本中提取更少量的基因组材料,”共同第一作者、TGen综合癌症基因组学部助理教授KamelLahouel博士说。“这一领域的持续成功和临床验证为引入常规测试以在早期阶段检测癌症打开了大门。”
Tomasetti准备于2024年夏季启动一项临床试验,以将这种片段组学血液检测方法与65-75岁成年人的护理标准进行比较。这项前瞻性试验将确定生物标志物组在检测更容易治疗的早期癌症方面的有效性。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。